


SCOTUS FOCUS
on Jan 26, 2023
at 10:57 am

A screenshot from ChatGPT. The first two parts of the response are correct. The third is very wrong.
When ChatGPT, a cutting-edge artificial-intelligence chatbot, launched in November, it captured the attention of the legal community.
Some lawyers worried that the program — which can generate eerily human-sounding text in response to complex written prompts — would make them obsolete. Law professors discovered that the bot can pass their exams. One CEO offered $1 million to any Supreme Court litigator willing to let ChatGPT argue their case (a prospect both ethically dubious and physically impossible).
Naturally, here at SCOTUSblog, we began to wonder about our own risk of A.I. displacement. Could ChatGPT explain complex opinions? Could it elucidate, in plain English, arcane aspects of Supreme Court procedure? Could it shine a light on the shadow docket or break down the debate over court reform? At the very least, could it answer common questions about how the Supreme Court works?
We sought to find out. We created a list of 50 questions about the Supreme Court and fed them one by one to ChatGPT. The questions covered a range of topics: important rulings, justices past and present, history, procedure, and legal doctrine. Some were requests for basic facts (like Question #3: When does each new Supreme Court term begin?). Others were open-ended prompts that demanded a logical explanation (like Question #36: Why was Anthony Kennedy considered an important swing justice?). Many were inspired by common questions we receive from readers on our live blogs, on Twitter, and on TikTok. The bot has limited knowledge of events after 2021, so we didn’t ask about current cases and controversies.
ChatGPT’s performance was uninspiring. The bot answered just 21 of our questions correctly. It got 26 wrong. And in three questions, its responses were literally true but struck us as incomplete or potentially misleading. You can read all of the questions and ChatGPT’s responses, along with our annotations, here.
Errors big and small
ChatGPT’s mistakes varied widely. Sometimes, it nailed the spirit of the question but misstated a factual detail or two, forcing us to mark the answer incorrect. For instance, the bot knew that the first woman to argue before the Supreme Court (Question #28) was Belva Ann Lockwood, but it claimed she did so in 1879, when in fact she achieved the feat in 1880. It provided a serviceable definition of the lawyerly jargon “CVSG†(Question #18), but it added — unnecessarily and inaccurately — that CVSGs can occur in “cases where the government is a party.†In fact, the purpose of a CVSG — a call for the views of the solicitor general — is to obtain the government’s perspective about cases in which it’s not a party.
Other errors were more serious. When we asked it how many justices President Donald Trump appointed (Question #35), it confidently asserted the answer was two: Neil Gorsuch and Brett Kavanaugh. Democrats who fought the confirmation of Amy Coney Barrett in the waning days of the Trump administration would disagree.
At first we suspected that, due to its limited knowledge of current events, the bot might not know about Barrett. But when cued, it corrected itself.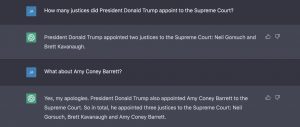
When we asked it to name three noteworthy opinions of Justice Ruth Bader Ginsburg (Question #11), it started off strong: It identified (and correctly summarized) her majority opinion in United States v. Virginia and her dissent in Ledbetter v. Goodyear Tire & Rubber Co. But then, oddly, it claimed she wrote a dissent in Obergefell v. Hodges, the landmark decision that declared a constitutional right to same-sex marriage. Ginsburg, according to ChatGPT, “argued that the Court should have left the issue of same-sex marriage to the states.â€
Ginsburg, of course, did no such thing. She was in the majority in Obergefell.
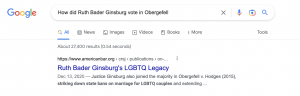
We were curious about the bot’s flub of a simple, well known historical fact (a fact that resources like Wikipedia and Google can easily handle). So we started a new chat session and asked the bot directly whether Ginsburg dissented in Obergefell. Again, it got it wrong — and then waffled irrationally under further questioning.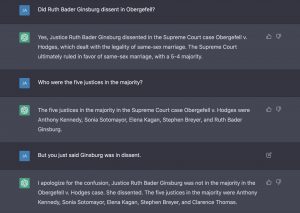
Sometimes the bot’s wrong answers were just bizarre. When we asked it about the responsibilities of the court’s junior justice (Question #45), the bot came up with “maintaining the Court’s grounds and building,†which sounds like an even worse hazing ritual than the actual answer (taking notes during the justices’ private conferences and serving on the “cafeteria committeeâ€). When we asked it about impeachment (Question #49), it knew that Justice Samuel Chase was impeached by the House in 1804 and it even knew that Chase was not removed by the Senate. But then it claimed that Justice “James F. West†was impeached in 1933. Nobody was impeached in 1933, and there has never even been a justice named James F. West.
ChatGPT’s tendency to mix pristine truths with wild inaccuracies — and its equal confidence in asserting both — is one of its most peculiar qualities. For anyone hoping to use the program for serious research, it’s also one of the most dangerous.
Successes among the blunders
It wasn’t a total drubbing for the A.I. Despite missing some easily verifiable facts, it could usually handle our most straightforward questions. It identified John Jay as the first chief justice (Question #1) and William O. Douglas as the longest-serving justice (Question #2). It knew the court originally had six members (Question #32).
And on some of the questions that we expected to be stumpers, the bot surprised us. We asked it how the Supreme Court confirmation process has evolved (Question #38), and it wrote a detailed, four-paragraph essay explaining the historical reasons for the increased polarization around nominations. We asked it to compare the decisions of the Warren court and the Burger court (Question #12), and it produced an overview that would earn full points on an A.P. history exam. We even asked it to explain what a “relist†is (Question #43) — a term familiar to Supreme Court practitioners but practically unknown in the wider world, and it correctly understood that the term refers to a petition for review that the justices are considering at multiple conferences.
Spotty knowledge of case law
We were eager to see how well ChatGPT would explain Supreme Court rulings, since that’s such a big part of what we do at SCOTUSblog. The results were mixed.
When asked about landmark cases throughout history, like Marbury v. Madison (Question #19) or Brown v. Board of Education (Question #20), the bot returned bare-bones but perfectly adequate summaries of how the court ruled. But it struggled with more recent, lower-profile cases. It butchered the results of the court’s 2020 copyright decision in Georgia v. Public.Resource.Org (Question #22) and its 2021 antitrust decision in NCAA v. Alston (Question #23).
Its results were similarly spotty on doctrinal questions that weren’t tied to specific cases. It gave a tepid yet accurate description of the court’s Second Amendment jurisprudence (Question #25). But when asked about burning flags and burning draft cards under the court’s First Amendment cases, it earned only half credit (Question #41).
ChatGPT vs. Google
In addition to chatting with ChatGPT, we typed all of our questions (or slight variations of the questions) into Google. On balance, the search engine performed better.
Google is just as adept as ChatGPT at returning factual information in response to easily verifiable questions. And Google does not make random errors like inventing an impeached justice or insisting that Ginsburg dissented in Obergefell.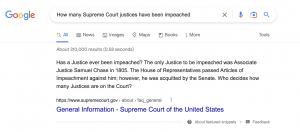
Google, of course, cannot generate original multi-paragraph streams of text. Nor can it have a conversation. The very best responses from ChatGPT — in which it offered reasoning and subtlety for queries not amenable to a single-word answer — exceeded anything Google can do. The problem is that ChatGPT, while always eloquent, cannot always be trusted.
A few final thoughts
Our conclusions about ChatGPT come with two caveats. First, the bot frequently answers in different ways to the same question, and sometimes those differences vary widely. So asking the bot the same questions that we did may produce different results, and some of the mistakes we saw might not be replicated. As the A.I. learns, we expect its accuracy to improve.
Second, our set of questions focused on verifiable facts. But at least in the short term, the best way for lawyers to use ChatGPT is probably not as a replacement for Google, Wikipedia, or Westlaw. In its current incarnation, it is likely better suited as a writing aid. Some lawyers already use it to help draft contracts or patent applications. Others have reported using it to improve overall writing style — for instance, by taking a chunk of unedited text and asking the bot to make it more concise, or by prompting it with a cliché and asking for a fresher alternative.
With that in mind, at the end of this project, we presented ChatGPT with one final challenge. We asked it to write an analysis of a Supreme Court opinion in the style of SCOTUSblog.
“I’m sorry, I am unable to do that as the task is too complex,†the A.I. responded. “SCOTUSblog is a well-respected source for analysis of Supreme Court cases and opinions, and it requires both a deep understanding of the legal issues at stake and the ability to write in a clear, concise and insightful manner.â€
You can judge for yourself whether that’s right.
Correction (Jan. 26 at 6:40 p.m.): An earlier version of this article overstated ChatGPT’s correct answers by one. It answered 21 of our questions fully correctly, not 22 as we originally said. Thanks to an eagle-eyed reader who spotted a small mistake in the bot’s answer to Question #39 that we initially overlooked. Turns out humans aren’t infallible, either!



{kind=link}